Artikkelissa tarkastellaan keskeisiä periaatteita audiovisuaalisen datan kuvaamisesta sellaisessa muodossa, että sitä voidaan joustavasti hakea sisällön mukaisin kuvauksin tietokannoista, massamuistitallenteista tai verkosta. Kuvaukset voivat olla metadataa, eli tekstuaalista kuvausta sisällöstä tai medialähtöistä dataa joka pohjautuu mediasta irrotettuihin piirteisiin, kuten esimerkiksi tekstuuriin, muotoon, liikkeeseen tai ääneen.
Median määrä kasvaa
80-luvun alusta lähtien on esiintynyt voimakas trendi saattaa audiovisuaalinen data sellaiseen muotoon, että sitä voidaan tehokkaasti tallentaa, hakea ja jakaa digitaalisesti. Luonnollisia näkymiä sisältävälle videolle on syntynyt joukko standardeja, joista uusimalla H.264:llä voidaan kompressoida PAL-laatuista videota lähes 1.2 Mb/s. Samoin on kehitetty joukko audiota kompressoivia algoritmeja, joista uusimpana on AAC ja tämän johdannaiset. Keinotekoista AV-dataa varten on myös kehitetty suuri joukko parametrisoituja kuvauksia. Jopa kokonaisten virtuaalisten maailmojen kuvaamiseksi esiintyy digitaalisia kuvauskieliä - mainittakoon tässä yhteydessä VRML 97 ja X3D. Vastaavasti tietokoneiden kovalevyjen tallennuskapasiteetti on kasvanut huikeasti. Tavallinen koti-PC sisältää tyypillisesti 50 - 80 G tavun massamuistilaitteen. Ohjelmien tallentamiseen ei näin paljoa juurikaan tarvita, mutta heti kun tallennetaan lomamatkan kuvat, muutama videoleike ja musiikkiesityksiä, tulee raja helposti vastaan. Mikäli Mooren laki pitää paikkansa, on muutaman vuoden kuluttua jo tavallisissakin laitteissa teratavu massamuistia. Siis digitaalisen informaation määrä kasvaa huikeasti ja tämä kasvanut määrä voidaan tallentaa tehokkaasti. Ongelmaksi muodostuu nyt, miten tästä massasta voidaan löytää tiettyyn käyttökohteeseen sopivin.
Digitaalisen sisällön määrä on kasvanut räjähdysmäisesti. Jonkinlaisen kuvan tuotetun median määrästä voidaan saada oheisesta, vuonna 2000 julkaistusta tilastosta (Lyman P., Varian H.R.: How much information 2000):
| Vuosittainen yksityisen informaation tuotanto | ||
| Nimikkeitä | Teratavuja | |
| Valokuvia | 80 miljardia kuvaa | 410 000 |
| Kotivideoita | 1.4 miljardia nauhaa | 300 000 |
| Röntgen kuvia | 2 miljardia kuvaa | 17 200 |
| Kovalevyjä | 200 miljoonaa | 13 760 |
| Yhteensä | 740 960 | |
| Teratavuilla tarkoitetaan median muistintarvetta kohtuullisella kompressiolla. | ||
Vuonna 1999 arvioitiin, että 93 prosenttia julkaistusta informaatiosta on digitaalisessa muodossa. Myös yksityinen informaatio siirtyy yhä enemmän digitaaliseen muotoon. Olisi toivottavaa, että löydettäisiin yleisesti hyväksyttyjä mekanismeja, joilla voitaisiin helposti löytää ja yhdistää sisältökomponentteja suuren massan joukosta.
Uusi ongelma-alue on monet agenttipohjaiset järjestelmät. Tässä ajatellaan paradigmaa, jossa älykäs ohjelmisto oppii käyttäjältä tämän kiinnostuksen kohteet ja käytöstavat ja pystyy välittämään nämä seikat muille medialäheisille agenteille. Jotta tällainen agentti voisi toimia digitaalista AV-dataa sisältävissä ympäristöissä, pitää audiovisualinen data kuvata sellaisella tavalla, joka luonnehtii mahdollisimman hyvin datan sisältöä. Toiseksi data pitää voida tallentaa hallitusti ja tavalla, joista agenttien välisen vuorovaikutuksen kautta voisi välittyä tieto loppukäyttäjälle.
Sisältö on arvokasta vain jos sitä pystytään käyttämään ja siihen voidaan osoittaa. Toistaiseksi sisällön hakua on tehty selainten avulla käyttämällä sopivia avainsanoja ja indeksejä. Tällainen erilaisilla hakukoneilla tehtävä haku luo valitettavasti huomattavan määrän kohinaa. Hakuprosessi on myös kohtalaisen kallis ja hinta kasvaa sisällön määrän kasvaessa. Tekstuaaliset kuvaukset ovat usein sekä subjektiivisia että puutteellisia ja rajoittuneet valitettavan usein vain tiettyyn sovellusalueeseen tai eivät kuvaa median sisäisiä suhteita kovin hyvin. Jokainen meistä on varmaan käyttänyt Internetissä erilaisia hakukoneita ja turhautunut siihen, että vastauksia on tullut liian paljon tai hakusana ei ole kuvannut haettavaa asiaa kovin hyvin. Olisihan toivottavaa, että voitaisiin viheltää tai soittaa jokin melodian pätkä ja kone hakisi kaikki liittyvät kappaleet automaattisesti tai piirtää muutamalla vedolla luonnos huonekalusta ja tietovarastosta voitaisiin hakea kaikki luonnokseen läheisesti liittyvät huonekalut.
On siis syntynyt kokonaan uusi ongelma-alue: miten voidaan kuvata, indeksoida ja annotoida kompressoimaton tai kompressoitu audiovisuaalinen data käyttäen työkaluja, jotka automaattisesti irrottavat audiovisuaaliset piirteet sisällöstä ja täydentävät tosinaan käsin tehtyjä tekstuaalisia kuvauksia. Ongelma ei ole pelkästään rajoittunut median tuottajan ongelmaksi vaan laajentunut koskemaan kaikkia, jotka tuottavat dataa digitaalisesti tai kuluttavat digitaalisesti tallennettua dataa.
Standardointi
Edellä mainittujen ongelmien ratkaisuksi päätti standardointiorganisaatioiden ISO ja ITU MPEG-yhteisö (Motion Picture Expert Group) 1996 Tampereella pidetyssä kokouksessa käynnistää uuden standardointiaktiviteetin, jonka tuloksena luotiin multimedian sisältöä käsittelevä uusi standardi MPEG-7, Multimedia Content Description Interface (ISO/IEC 15938). Standardointiaktiviteetti oli valtava, ehdotuksia saapui 625, joiden arvioinnin tuloksena syntyi MPEG-7. Standardi on luonteeltaan ns. toolbox-standardi, joka sisältää hyvin suuren mutta kuitenkin minimaalisen määrän erilaisia (toistensa poissulkevia) työkaluja ja menetelmiä (Pereira 2002: Introduction to MPEG-7). MPEG-7 muodostuu kahdeksasta osasta:
Systems: määrittelee kaikki ne mekanismit ja työkalut, joita tarvitaan MPEG-7-kuvausten ja työkalujen tehokkaaseen siirtämiseen ja tallentamiseen sekä sisällön synkronointiin
Description Definition Language: määrittelee kielen, jolla voidaan kuvata ns. deskriptorimalleja eli median kuvailumalleja.
Visual: määrittelee kuvaukset (deskriptorit) ja deskriptorimallit, joita sovelletaan visuaaliseen tietoon.
Audio: määrittelee audiodatan käsittelyyn soveltuvat deskriptorit ja deskriptorimallit.
Generic entities and Multimedia Description Schemes (MDS): määrittelee geneerisiä (ei siis audio tai video spesifejä) deskriptoreita ja deskriptorimalleja.
Reference Software: kuvailee MPEG-7:ään sisältyvien menetelmien ns. referenssi-implementaatiota
Conformance Testing: määrittelee yhteensopivuustestausprofiilit eli menettelytavat joilla voidaan testata tietyn implementaation standardinmukaisuus.
Extraction and Use of MPEG-7 Description: julkaisu ei oikeastaan ole standardin normatiivinen osa. Siinä annetaan kuva miten audiovisuaalista dataa voidaan irrottaa osaksi kuvauksia ja miten käytännössä käytetään eräitä deskriptorimenetelmiä.
Tarkastellaanpa lukijan motivoimiseksi oheista kuvaa. Tässä media on stillkuva, jossa on luonnehdittu keskeisiä kuvauksessa esiintyviä tekijöitä. Näitä tekijöitä ovat sisällön hallinnointiin, spatiaalisiin ja sisältöön liittyviä seikkoja.
Sisällön hallinnointiin liittyviä tekijöitä ovat luontia, mediaa ja käyttöä kuvailevat tiedot. Luontia luonnehtivilla tiedoilla pyritään vastaamaan kysymykseen kuka, koska ja missä kuva luotiin. Samoin tässä voidaan vastata kysymykseen, mitä välineitä käytettiin. Mediaan liittyvillä tiedoilla pyritään hahmottamaan, mikä on median formaatti (720 x 437, JPEG-koodaus) ja minne se on tallennettu. Käyttötietoihin on usein tallennettu tieto, kuka ja millä ehdoilla mediaa saa käyttää. Tämän kaltaiset tiedot liittyvät läheisesti kuvaan, mutta eivät varsinaisesti esitä kuvan sisällöstä mitään. Esimerkkikuvan tapaus on sinänsä yksinkertainen yksi kuva yhdestä tapahtumasta ja yhdellä koodaustavalla (720x437 JPEG). Usein kuvia voi olla tietystä tapahtumasta paljon, useamman eri kuvaajan kuvaamana, eri kuvakulmilla ja tallennettu eri formaateilla. Tällaista tapahtumaa (esimerkiksi urheilutapahtuma) kutsutaan MPEG-7-kielenkäytössä realityksi, jota siis media esittää.
Esimerkkikuvasta on koodattu kuvan spatiaalisia suhteita ja alueita kuvaavia seikkoja (SR-1, SR-2 ja SR-3). Tässä on esitetty alueiden värirakenne - monia muita seikkoja olisi voitu esittää, esimerkiksi tekstuuri ja muoto. Osakuvasta SR-3 on myös esitetty, miten se liittyy varsinaiseen kuvaan. Alueiden spatiaalinen dekompositio on myös kuvattu (segmentit eivät peitä toisiaan). MPEG-7:ään sisältyvät sisällön rakennetta esittävät seikat kuvaavat median spatiaalisia ja temporaalisia piirteitä kuten myös lähteen segmenttejä ja näiden välisiä suhteita. Tähän voidaan sisältää hyvinkin mutkikkaita hierarkisia kuvauksia. Esimerkiksi 3D-kuvassa voidaan kuvata osien syvyyssuunnassa olevia suhteita, videosegmenteista voidaan kuvata siirtymiä segmentistä (otoksesta) toiseen, kollaasista osakuvien suhdetta kokonaisuuteen jne. MPEG-7:n kuvaustavat ovat tässä erittäin monipuoliset. Esimerkin kolmas osa-alue muodostuu kuvan semantiikasta eli siitä, mitä kuva oikeastaan esittää: Anni ja Mikko pitävät toisiaan kädestä ja keskustelevat ystävällisesti keskenään. Multimedian kontekstuaalinen (sisällön) semantiikka usein aloitetaan kuvaamalla mediassa esiintyviä tapahtumia (keskustelevat, pitävät toisiaan kädestä). Kuvaukseen voidaan lisätä ihmiset ja organisaatiot (joita kutsutaan MPEG-7 kielenkäytössä agenteiksi), tapahtumapaikat, rakennukset jne. Lisäksi kaikilla näillä tapahtumaan osallistuvilla seikoilla on keskinäinen suhde (esimerkiksi Anni ja Mikko seisovat oven edessä) ja erilaisia tiloja. MPEG-7 sisältää hyvinkin monipuoliset työkalut semanttiseen abstraktointiin (esimerkiksi toveruus, kaksi ihmistä vuorovaikuttavat keskenään), joita voidaan tarkentaa erilaisin attribuutein (Anni, Mikko, keskustelevat). Samoin abstraktioiden ja niiden attribuuttien välisiin suhteisiin esiintyy myös laaja valikoima erilaisia menettelyitä.
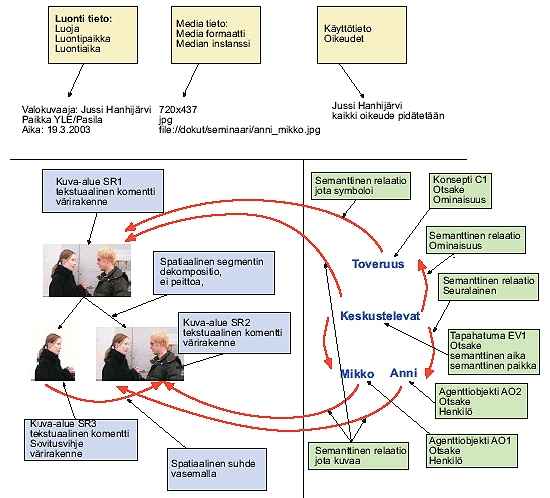
Keskeisiä MPEG-7:n piirteitä
Käytettävä kuvauskieli oli eräs MPEG-7:n standardoinnin peruskysymyksistä. Useista eri ehdotuksista valittiin XML-kieleen (eXtended Markup Language) perustuva DDL (Description Definition Language). Kielellä määritellään multimediadatan liittyvien kuvausten varsinainen sisältö. DDL ei ole mallinnuskieli kuten UML, vaan schema-kieli (mallikieli), jolla voidaan kuvata datamalleja. DLL määrittelee deskriptoreiden ja deskriptorimallien syntaksin, rakenteen ja rakenne-elementtien arvot. DDL:n pitää kyetä ilmaisemaan deskriptoreeihin sisältyvien elementtien strukturaaliset, periytymis-, spatiaaliset, temporaaliset, spatiotemporaaliset ja käsitteelliset piirteet sekä näiden väliset suhteet. DDL pohjautuu siis hyvin pitkälle XML-Schema kieleen, vaikka tämä ei ole suunniteltu AV-datan kuvaamiseen. Tämän vuoksi DDL:ään on lisätty multimediakuvausten vaatimat tietorakenteet.
XML-Schema muodostuu kolmesta schemakomponenttien muodostamasta luokasta. Näitä ovat ensisijaiset, toissijaiset ja avustavat komponentit. Ensisijaiset komponentit ovat sellaisia, joilla voidaan muodostaa yksinkertaisia XML-kuvauksia jo yksinään. Näitä ovat erilaiset tunnisteina käytettävät nimiavaruudet, alkeellisten elementtien ja attribuuttien luonteen selvitykset (declaration) sekä erilaiset tyyppimääritykset. Toissijaisiksi komponenteiksi on määritelty ne komponentit, joilla voidaan luoda ja nimetä erilaisia attribuuttien tai elementtien muodostamia ryhmiä. Näitä voidaan sitten käyttää edelleen monimutkaisemmissa tyyppimäärityksissä. Lopuksi avustavilla komponenteilla voidaan täydentää näitä kuvauksia.
MPEG-7 sisältää satoja valmiiksi määriteltyjä XML-Schema komponentteja, joita käytetään ns. multimedian deskriptorimallien (MDS multimedia description scheme) muodostamiseksi. MDS:llä voidaan rakentaa hyvinkin monipuoliset sisällön kuvaustavat:
- perustyypeillä kuvataan sellaisia seikkoja joita tarvitaan usein, esimerkiksi linkitys ja lokalisointitietoja, ihmisiä ja organisaatioita kuvaavia tietoja, näiden välisiä suhteita, ajoitustietoja jne.
sisällön hallintaan liittyvissä seikoissa kuvataan mm. se miten media on luotu (tekijät, paikat välineet jne.), koodaustavat ja median käyttöön sisältyvät erilaiset seikat ja rajoitukset.
sisällön kuvauksissa kuvataan rakenne (esimerkiksi videon sisältyvät framet ja audion segmentit) ja sisällön semantiikka (objektit, tapahtumat ja erilaiset abstraktit notaatiot)
navigointia ja saantia kuvaavissa seikoissa helpotetaan median hakua, näitä ovat erilaiset yhteenvedot, erilaiset vaihtoehtoiset näkymät itse mediasta, tieto eri kielisten versioiden olemassaolosta jne.
Sisällön organisointia kuvaavissa seikoissa taasen kuvaillaan sisältökokoelmia esimerkiksi jaoteltuna tapahtumien ja esiintyvien kohteiden (mm. henkilöiden) mukaan.
- Käyttäjän vuorovaikutusta kuvaavissa seikoissa käsitellään käyttäjälle asetettavia mahdollisia mieltymyksiä (preferenssejä) ja käyttöhistoriaa. Tällä tavalla voidaan mallintaa esimerkiksi multimedian personoitua saantia, esitystä ja kulutusta