Videokompressio on merkittävästi kehittynyt 1980 luvun alkupuolen koodekeista nykyisin käytössä oleviin monimutkaisiin kuvan ja äänen tiivistysmenettelyihin. Tyypillinen esimerkki varhaisesta koodekista oli Haikonen-Korhonen-Santamäki kolmikon kehittämä kotimainen Vistaphone. Laite oli rakennettu Intel 8 bitin kontrollerin 8051 ympärille. Kukin lähettävä kuva muodostui melko suurista lohkoista ja vastaanottajan kuvaa päivitettiin lähettämällä vain peräkkäisten kuvien erotus. Laite kykeni välittämään tunnistettavaa "videota" 64 kb/s:n nopeudella X.25 verkossa. Mitään muunnosalueen koodausta tai entropiakoodausta siinä ei käytetty. Tänään voimme lähettää uusimmilla standardeilla jakelulaatuista videota siirtonopeudella n. 1,5 - 2 Mb/s. Näissä järjestelmissä käytetään tehokasta useammasta peräkkäisestä kuvasta muodostettuja liikevektorien ennusteita, kosinifunktioihin pohjautuvaa muunnosalueen koodausta ja kehittynyttä entropia-koodausta.
Vaikka koteihin jaettavan laajakaistaisen Internetin nopeudet ovat jatkuvasti kasvussa, tuottavat nykyisin standardoidut kompressiomenettelyt silti vielä liian nopeita bittivirtoja yleisradiolaatuisen videon siirtämiseksi koteihin. Esimerkiksi DVB:ssä käytetyn MPEG-2:n nopeudet ovat luokkaa 1,5 - 5,5 Mb/s. Eräänä keinotekoisena rajana on pidetty reaaliaikaisen jakelulaatuisen videon, 720x576x24 bpp (bit per picture), 25 kuvaa sekunnissa, lähettämistä ja vastaanottamista 1 Mb/s siirtonopeudella ADSL- tai kaapelimodeemien kautta. Vaatimus on vajaa puolet siitä mitä uusimmat standardit H.263++ ja H.26L (H.264) lupaavat. Oheiseen kuvaan on hahmoteltu standardoidun videokompression kehitystrendejä, kuvapuhelinsovelluksissa.
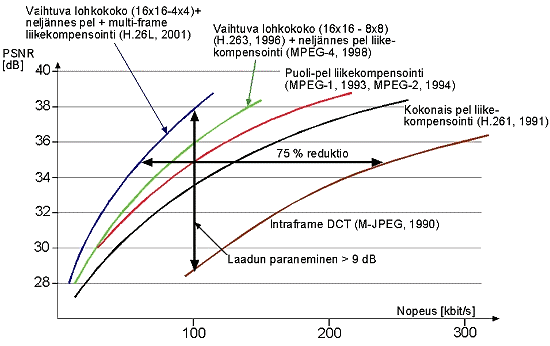
Kompressiostandardien kehitystrendejä
Kuvasta nähdään selvästi, että mikäli kehitystrendi jatkuu samanlaisena saavutetaan mainittu "haamuraja" parin vuoden sisällä.
Miksi kompressoida?
Miksi audiota ja videota pitää kompressoida? Siitä saamme jonkinlaisen kuvan oheisesta taulukosta.
|
Taulukkosta nähdään selvästi, että varsinkin video ja audio vaativat huomattavaa kompressiota, jotta multimediadata voitaisiin siirtää ja tallentaa kohtuullisin kustannuksin ja vaadittavin nopeuksin.
Videon lähdemalli
Valtaosa koodattavasta luonnollista dataa sisältävästä videosta on luonteeltaan stokastista, satunnaista, siinä mielessä, että valoisuus, värit ja liikkeet määräytyvät epädeterministisesti. Yksittäisten kuvien (kenttien) muodostamat sekvenssit sisältävät yleensä runsaasti sekä alueellista että ajallista toistoa eli redundanssia. Kuvaelementtien välillä on tietty korrelaatio ja liikkeet ovat joko siirtymiä, kiertymiä ja/tai supistuvia tai laajenevia luonteeltaan. Tietyn kuva-alkion arvo voidaan usein ennustaa sen naapurialkioista tai edeltävien tai seuraavien kuvien (kenttien) vastaavista alkioista. Edellisessä tapauksessa puhutaan kuvan sisäisestä (I-frame, intra-frame) koodauksesta ja jälkimäissä kuvien välisestä (P-frame, predicted frame) koodauksesta ja liikkeen ennustamisesta. Kun kuvien välinen sisällöllinen korrelaatio on alhainen eli kuvien sisällössä on paljon vaihtelua, on myös ajallinen (temporaalinen) korrelaatio alhainen tai jopa häviää, kun kuvat ovat täysin erilaiset. Jälkimmäisessä tapauksessa kuvan sisäisen kompression tarve kasvaa suureksi, jotta mielekästä virheetöntä kompressoitua videota voitaisiin lähettää. Toisaalta jos peräkkäisten kuvien välinen korrelaatio on suuri (esimerkiksi kuvat sisältävät paljon samoja elementtejä eri tai samoissa paikoissa) on kuvien välisellä koodauksella, liikevektoreiden estimoinnilla, suuri osuus temporaalisten piirteiden kompressoimiseksi. Teoreettisissa suoritus- kykytarkasteluissa mallinnetaan usein kuva-alkioiden välistä kuvansisäistä korrelaatioita Gaussin stokastiikalla ja kuvien välistä korrelaatioita Markov-ketjuilla (tilasiirtymästokastiikoilla). Monissa tapauksissa lähetettävä video muodostuu keinotekoisesta datasta. Usein riittää kompression sijasta lähettää dataa identifioivat parametrit. Muutokset voivat olla jollain tavalla parametroitavissa. Esimerkiksi ihmiskasvoista voidaan lähettää kuvan lisäksi kasvon piirteitä kuvaava verkko (mesh). Vastaisuudessa, kun halutaan kasvojen irvistävän, lähetetään vain verkon irvistysparametrit.
Koodekin elementit
Videon ja kuvien koodaus voidaan jakaa karkeasti kahteen luokkaan, häviölliseen ja häviöttömään koodaukseen. Häviötöntä koodausta pyritään käyttämään silloin, kun informaation hankinta, tallennus ja siirto on kallista, kuten esimerkiksi satelliitti- ja lääketieteellisissä sovelluksissa. Häviöllistä koodausta käytetään silloin, kun kuviin tai videoon liittyvää redundanssia eli toistoa voidaan uhrata esimerkiksi siirto- tai tallennuskustannusten pitämiseksi mahdollisimman alhaisena. Usein objektiivisen oikeellisuuden sijasta riittää alkuperäisen ja koodatun videon subjektiivinen samankaltaisuus eli riittävän hyvä laatu. On tärkeää huomata, että kuvan vääristymät (sekä objektiiviset muutokset että silmin havaitut vääristymät) ovat riippuvaisia sekä koodausmenetelmästä että kuvan kompleksisuudesta.
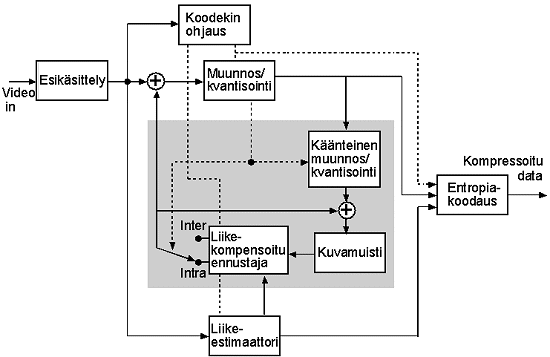
Tyypillinen enkooderin rakenne
Videon ja kuvan kompressio muodostuu useamman tekniikan ja algoritmin yhteisvaikutuksesta.
Esikäsittely
Ennen varsinaista videon enkoodausta digitoitu signaali usein alinäytteistetään. Ajatuksena on pienentää videokuvan kokoa pysty ja/tai vaakasuunnassa. Toisinaan alinäytteistetään myös aika-alueessa kenttä- tai kuvataajuuden pienentämiseksi. Alinäytteistämistä käytetään usein myös värisignaalin subjektiivisen redundanssin vähentämiseen. Kyse on itse asiassa siitä, että ihminen havaitsee helpommin kirkkauden kuin värin vaihtelut. Usein videodata jaetaan yhteen luminanssi- ja kahteen krominanssikanavaan (YUV). Krominanssikanavat alinäytteistetään suhteessa luminans- sikanavaan, esimerkiksi suhteessa 4:2:2 (neljä näytettä luminanssille ja kaksi kummallekin krominanssikanavalle. - Alinäytteistäminen on ehkä yksinkertaisin kompressiotekniikka.
Ennusteiden muodostus
Ennustavassa koodauksessa videosta etsitään redundanssia tutkimalla, onko paikallisesti tai ajallisesti lähekkäisten kuva-alkioiden välillä vahva korrelaatio. Ennuste koodattavalle kuva-alkiolle muodostetaan jo lähetetyn (tai koodatun) informaation perusteella. Alkion todellisen arvon ja ennusteen välinen ero kvantisoidaan ja entropiakoodataan. Tekniikka on johdannainen hyvin tunnetusta differentiaalisesta pulssikoodimodulaatiosta (DPCM).
Liikkeen estimointi
Liikkeen estimointia ja kompensointia käytetään vähentämään peräkkäisten kuvien välistä ajallista redundanssia. Esimerkiksi liikkuvaa kohdetta kuvattaessa kuvan kaikki elementit siirtyvät hieman. Kenttien välinen liike voidaan kuvata likimääräisesti äärellisellä määrällä liikeparametrejä (estimoiduilla liikevektoreilla). Ennustevirhe ja liikevektorit lähetetään vastaanottajalle. Yleensä ei ole tarpeellista lähettää liikeinformaatiota jokaiselle koodatulle kuva-alkiolle. Koska yksittäisten kuva-alkioiden liikevektoreiden välinen korrelaatio on yleensä vahva (liikkuvat samaan suuntaan!), yksi liikevektori voi kuvata monen alkion muodostaman kokonaisuuden liikettä. Monissa koodekeissa lohkot ovat melko suuria, esimerkiksi MPEG-2:ssa kooltaan 16x16 kuva-alkiota. Uusimmissa standardeissa liikevektorit muodostetaan ennustustarkkuuden parantamiseksi useamman peräkkäisen kuvan perusteella.
Muunnosalueen koodaus
Muunnosalueittain koodauksen ensisijaisena tavoitteena on poistaa kuvan sisäinen redundanssi ja muodostaa muunnoskertoimet, jotka enkoodataan kuva-alkioiden sijasta. Monissa vakiintuneissa kompressiomenetelmissä kuva jaetaan kuva-alkioiden muodostamiin lohkoihin (esimerkiksi digitv:n MPEG-2:ssa kooltaan 8x8 pikseliä). Ollakseen tehokas pitää muunnosalueen koodauksen olla sellainen, että mahdollisimman harvoilla kertoimilla voidaan muodostaa koodattava lohko.
Tehokkaan muunnoksen tekemiseen on ehdotettu lukuisia eri menetelmiä. Toistaiseksi valintaa on säännellyt eri menetelmien kustannukset enkoodauksessa ja dekoodauksessa sekä mahdollisuus toteuttaa menetelmä VLSI-piireillä. Yleisimmin käytetyt muunnokset ovat:
- Diskreetti kosinimuunnos DCT (esim. JPEG-1, H.261, MPEG-1, MPEG-2, H.265)
- Aallokkeet (esim. JPEG-2000, MPEG-4,WaveVideo, SAMCoW)
- Vektorikvantisointi (esim. Cinepak, Indeo)
- Fraktaalikoodaus (esim. Iterated System)

| Diskreetin kosinimuunnoksen vaikutus kuvan laatuun muunnokseen mukaan otettavien kertoimien funktiona. Kuvasta nähdään, että jo kahdeksan kertoimen (64:stä) jälkeen kuvan laatu ei enää merkittävästi parane. |
Kvantisointi
Kvantisoinnin tehtävänä on vähentää koodattavien merkkien määrää. Kompressiossa se on yksi häviöllisimpiä tekijöitä. Menettelyssä koodattavat, tietyllä välillä olevat lukuarvot, pyöristetään yhteen, koko väliä edustavaan arvoon. Esimerkiksi luku 1,36 (välillä 1,00-1,99) kvantisoidaan arvoon 1, luku 2,17 (välillä 2,00-2,99) 2:ksi jne. Kvantisointi voidaan tehdä myös taulukoimalla tietyt lukuarvot vastaamaan tiettyä taulukosta luettua koodisanaa.
Entropia- ja RLC-koodaus
Muunnettu datavirta saattaa sisältää peräkkäisiä samoja koodisanoja. Saman koodisanan toistaminen on yleensä tarpeetonta ja kuluttaa vain käytössä olevaa siirtokapasiteettia. Datan redusoimiseksi erilaiset pituussuunnan koodit (Run Lenght Code, RLC) ovat osoittautuneet hyödylliseksi. Hyvin suunnitellussa RLC-koodaustavassa voidaan jopa yhdellä koodisanalla viitata suurempaan ryhmään tietynlaisena sekvenssinä esiintyviä koodisanoja.
Koodisanojen esiintymistodennäköisyydet ovat harvoin tasan jakautuneet. Useammin esiintyville koodisanoille on siis edullista valita lyhyemmät koodit kuin harvemmin esiintyville. Tätä kutsutaan entropiakoodaukseksi.
Tulevaisuuden näkymiä
Kuinka nopeita koodekkeja voimme itse asiassa rakentaa käyttäen muunnosalueen transformaatiotekniikoita, liike-estimaattoreita ja sopivaa entropiakoodausta ? Kirjallisuutta selatessa vaikutta siltä, että raja broadcast-laatuiselle videolle on jossain 750 kbit/s tietämillä. Rajan saavuttaminen edellyttää muutamien tutkijoiden pöydiltä lähtevien innovaatioiden soveltamista. Ensinnäkin muistipiirien halpenemisen myötä voimme tallentaa muistiin useammpia peräkkäisiä kuvia. Niiden pohjalta voimme muodostaa älykkäämpiä läpi monen kuvan ulottuvia ja sopivasti entropiakoodattuja liikevektoreita. Lähetettävää liikevektori-informaatiota saadaan näin vähennettyä ja voidaan rekonstruoida täsmällisempiä kuvia. Voimme siis lähettää intrakoodattuja kuvia harvemmin. Toinen tärkeä kehitystrendi on sisältöön mukautuva entropiakoodaus. Voimme käyttää yhden kiinteän koodaustaulukon sijasta useita tauluja aina sen mukaan, mitä muunnettu kuva tai videosarja sisältää luminanssi- ja krominanssiarvoilla kuvattuna. Vaikutta siltä, että lähetettävien koodisanojen keskimääräistä pituutta voidaan tällä tekniikalla lyhentää jopa 30 %.
Muitakin kehitystrendejä esiintyy. Kuten esimerkikksi fraktaalikoodaus tai kaaosteoriaan perustuva kompressio. Barnsley osoitti fraktaalikoodauksella saavutettavan jopa kompressiosuhteen 1:1000. On arveltu, että Bransleyn menetelmä vaatii kuvaa kohden 100 tuntia 2 GHz:n Pentium 4 -tasoisen keskusyksikön prosessointitehoa. Kuvia virtaa 25 kpl/s, joten on melko selvää, että Bransleyn käyttämää fraktaali-järjestelmää ei voida soveltaa suoraan.
Missä siis on kompression ehdoton alaraja? Vaikea sanoa. Toistaiseksi kukaan ei ole keksinyt hyvää algoritmia, jolla voitaisiin tehdä IFS:ään tai vektorikvantisointiin perustuvaa fraktaalimuunnosta kompressiosuhteella 1:1000 (tai suuremmalla) nopeasti ja automaattisesti.
Ihminen kykenee tähän, kuten Barnsley on osoittanut. Mahdollisesti algoritmit näin suuriin kompressiosuhteisiin löytyvät tekoäly-, "common sense reasoning"- ja tunnekonetutkimuksesta. Algoritmit, jos ne ylipäätänsä on keksittävissä, tulevat melko varmasti soveltamaan useampaa metodia ja tekniikkaa yhtäaikaa - kuten ihminen tekee kaiken aikaa.